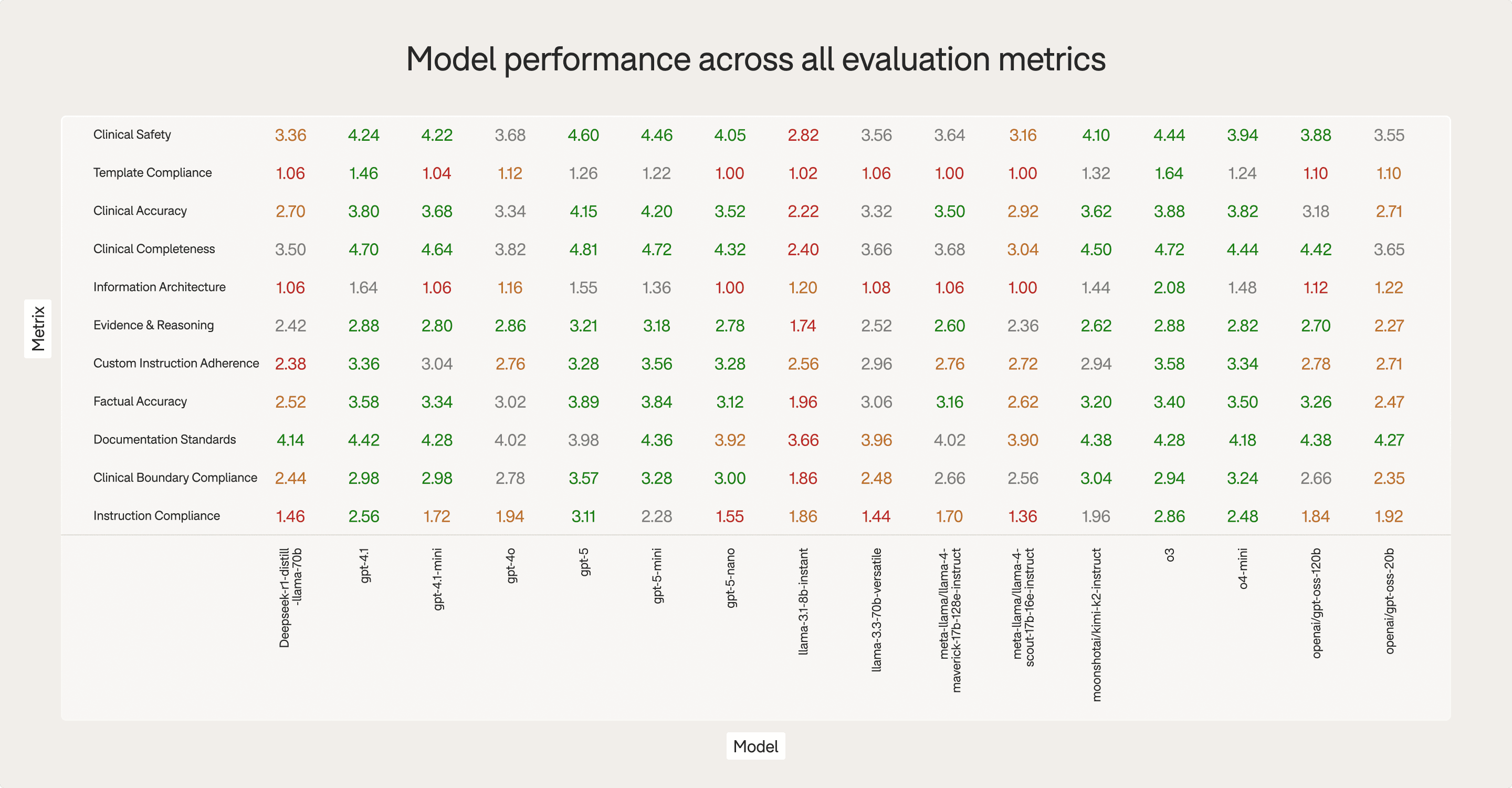
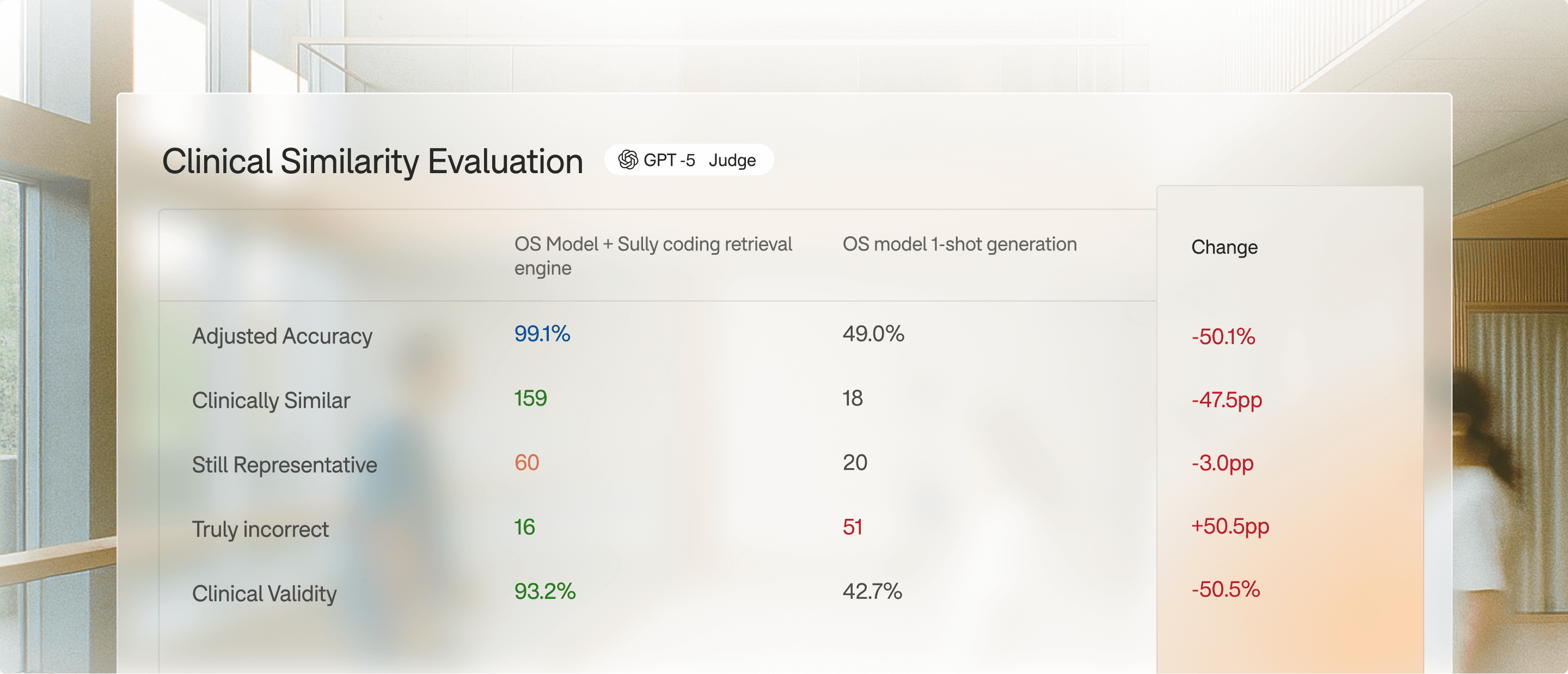
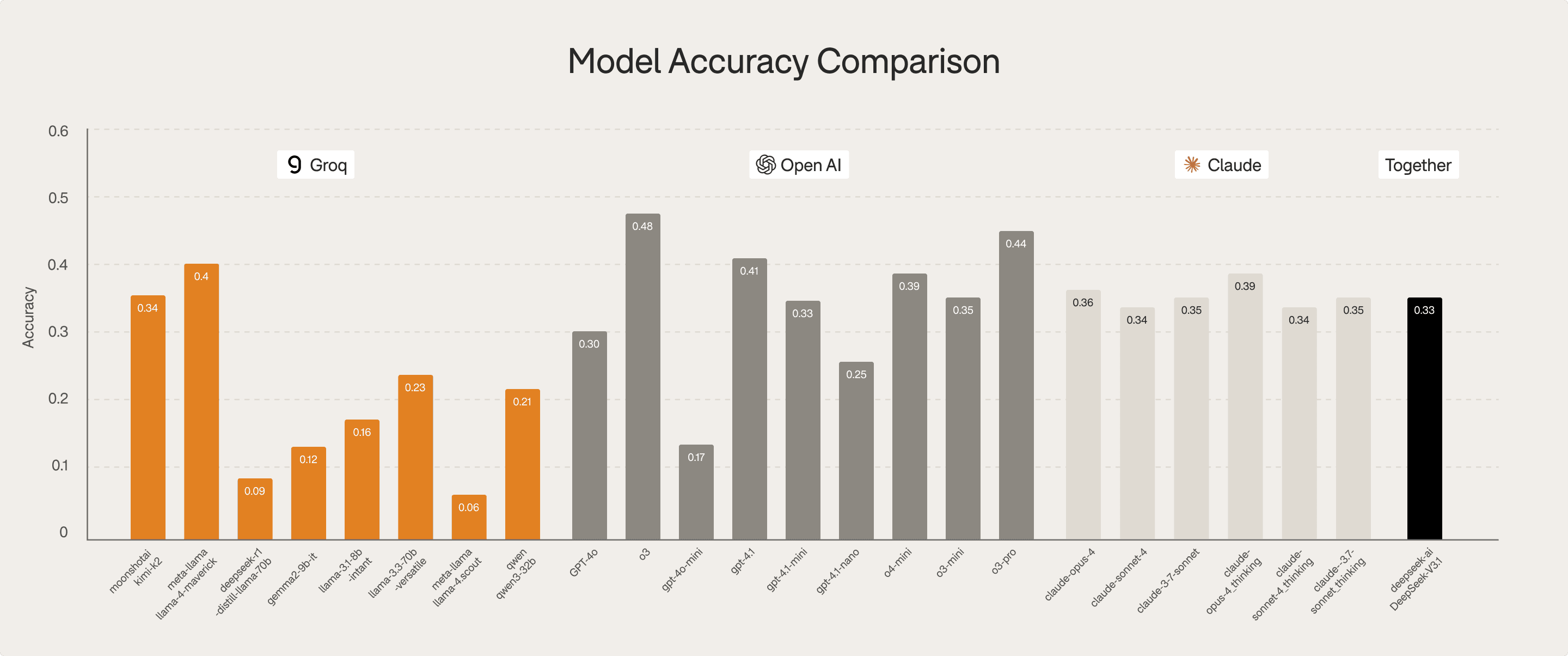
A continuously evolving benchmark of medical AI performance across clinical reasoning, documentation, and coding tasks.
What We Measure
Clinical knowledge accuracy
Diagnostic reasoning strength
Logical validity and hallucination rates
Safety and guideline adherence
Metrics Assessed
Completeness of medical content
Logical consistency and absence of hallucinations
Clinical validity
Adherence to note structure
Physician usability